Introduction aux modèles de langage
Sopra Steria
23 octobre 2024
IA ?
“Toute technologie informatique qui permet de résoudre des problèmes complexes qu’on aurait cru réservés à l’intelligence humaine.” – Cédric Vilani
L’évolution de l’IA
- 1960-1970 - Premiers travaux sur les réseaux de neurones
- 1966 - Shakey le robot (Stanford)
- 1980-2010 - Le machine learning se répand
- 11 mai 1997 - Deep Blue bat Kasparov aux échecs
- 2010-2022 - Explosion du deep learning
- 2017 - Architecture “transformer” de Google
- 2018 - GPT-1 par OpenAI
- 2022 - GPT-3 révolutionne l’IA conversationnelle
- 2023-aujourd’hui - IA multi-modales (to be continued)
Dans le monde de l’IA, où se situe GPT ?
- Machine learning - Les ordinateurs apprennent à partir de données sans être explicitement programmés.
- Deep learning - Sous-catégorie du machine learning qui utilise des réseaux de neurones artificiels pour apprendre et traiter des données complexes.
- LLM (Large Langage Model) - Modèles de langage capables de comprendre et générer du texte.
LLM, comment ca marche ?
Un LLM (Large Language Model) comme GPT-3 fonctionne en utilisant un réseau de neurones artificiels profond, mais pas que ! On va voir dans cette présentation les principes de bases de fonctionnement d’un LLM.
Mais globalement, comment fonctionne un LLM ?
Phase 1 : Entraînement
- Apprentissage sur d’immenses quantités de texte
- Comprend les patterns du langage
- Apprend à prédire les mots suivants dans une séquence
Phase 2 : Fine-tuning
- Adaptation à des tâches spécifiques
- Apprentissage sur des données ciblées
- Amélioration des performances pour un domaine particulier
Phase 3 : Inférence
- Utilisation du modèle entraîné
- Génération de réponses contextuelles
- Application des connaissances acquises
Du texte aux vecteurs
Le problème
- Les ordinateurs ne comprennent que les nombres
- Le texte doit être converti en représentation numérique
- Besoin de capturer le sens des mots
La solution
- Tokenisation : découpage du texte
- Embedding : conversion en vecteurs
Tokenisation
Définition
- Processus de découpage du texte en unités plus petites (tokens)
- Un token peut être un mot, une partie de mot, ou un caractère
- On donne un ID à chaque token
- Passage d’un espace infini (le langage) à un espace fini
Types de tokenisation
- Par mots
- Par caractères
- Par sous-mots
Exemple:
Texte : "J'aime les chats"
Tokenisation par mots :
["J'", "aime", "les", "chats"]
Tokenisation sous-mots (BPE) :
["J'", "aim", "e", "les", "chat", "s"]Tokenizer OpenAI (BPE)
Embeddings
C’est le passage d’un token à un vecteur de nombres, dans un espace de haute dimension.
Pourquoi des embeddings ?
- Capture le sens des mots
- Préserve les relations entre les mots
- Permet les opérations mathématiques
"chat" → [0.2, -0.5, 0.8, ...]
"chien" → [0.3, -0.4, 0.7, ...]
"voiture" → [-0.1, 0.2, -0.3, ...]Relations dans l’espace d’embedding
Propriétés sémantiques
Le placement dans l’espace des vecteurs donne les propriétés sémantiques, exploitable avec des calculs vectoriels.
vec(roi) - vec(homme) + vec(femme) ≈ reine
vec(Paris) - vec(France) + vec(Italie) ≈ RomeSimilarités
- Mots proches en sens = vecteurs proches dans l’espace
- On utilise simplement les distances cosines ou euclidéennes
- “chat” et “chien” plus proches que “chat” et “voiture”
Dimensions de l’embedding
Choix de la dimension
- Petite (32-100) : Modèles simples
- Moyenne (256-512) : Modèles standards
- Grande (768-2048) : Grands modèles
Impact
- Plus de dimensions = plus de nuances
- Mais aussi plus de calculs
- Compromis capacité/performance
Visualisation
Projetons les vecteurs :)
De l’embedding à l’attention
Processus complet
- Texte → Tokens
- Tokens → Embeddings
- Embeddings → Entrées pour l’attention
"J'aime les chats"
↓
["J'", "aime", "les", "chats"]
↓
[[0.1, 0.2, ...], [0.3, -0.1, ...], ...]
↓
Calcul de l'attentionLe mécanisme d’attention : La clé des LLM
Pourquoi l’attention ?
- Les anciennes approches (RNN) avaient des limitations
- Difficulté à gérer les longues séquences de texte
- Besoin de comprendre le contexte global
Exemple pour un RNN:
"J'ai grandi en France et j'ai appris le français. Je parle [couramment]"
↑___________________________________|- L’information de “France” est diluée avant d’arriver à “couramment”
L’attention en détail
- Permet au modèle de “peser” l’importance de chaque mot
- Crée des connexions directes entre les mots d’une phrase
- Trois concepts clés : Query, Key, Value
Comment fonctionne l’attention ?
- Query (Q) : Ce que le modèle cherche
- Key (K) : Les informations disponibles
- Value (V) : Le contenu à extraire
Formule simplifiée
$$ \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V $$
Où :
- Q (Query) : Matrice des requêtes, représente ce qu’on cherche à comprendre
- K (Key) : Matrice des clés, représente les informations disponibles
- V (Value) : Matrice des valeurs, contient le contenu réel
- dk :
Dimension des vecteurs de clés
- Dimension d’embedding / nb têtes d’attention, souvent 64-128
- KT : Transposée de la matrice K
- softmax : Fonction qui convertit les scores en probabilités (entre 0 et 1)
Multi-head Attention
- Plusieurs mécanismes d’attention en parallèle
- Capture différents types de relations
- Combine les résultats pour une meilleure compréhension
Perceptron multicouche (MLP)
Réseau neuronal feedforward. La propagation des données pendant l’inférence ne se fait que vers l’avant.
MLP simple
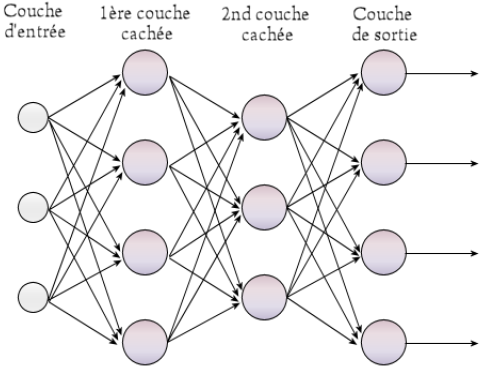
Rôles
- Le bloc d’attention permet de “trier” les mots
- Le MLP va faire les liens
Transformer visualisé
- Permet de voir l’attention en action
- Montre les connections entre les mots
- Illustre les différentes têtes d’attention
Comparaison
Traduction de “It’s raining cats and dogs”
| Modèle | Entrée | Sortie |
|---|---|---|
| Rule-based | It’s raining cats and dogs | Il pleut des chats et des chiens |
| SMT | It’s raining cats and dogs | Il pleut beaucoup |
| Transformer | It’s raining cats and dogs | Il pleut des cordes |
Résumé
Un mécanisme d’attention est la capacité d’apprendre à se concentrer sur des parties spécifiques d’une donnée complexe. Il peut aider un réseau de neurones artificiels à apprendre sur quoi “se concentrer” lorsqu’il fait des prédictions et donc pas la suite “prédire” le mot “logique” suivant les précédents.
Ce mécanisme est efficace car parallélisable.
Architecture Transformer
Vue d’ensemble
- Architecture basée sur l’attention
- Pas de récurrence ni de convolution
- Traitement parallèle efficace
Composants principaux
- Encodeur
- Traite le texte d’entrée
- Plusieurs couches d’attention
- Crée une représentation riche
- Décodeur
- Génère la sortie
- Attention masquée
- Attention croisée avec l’encodeur
Architecture
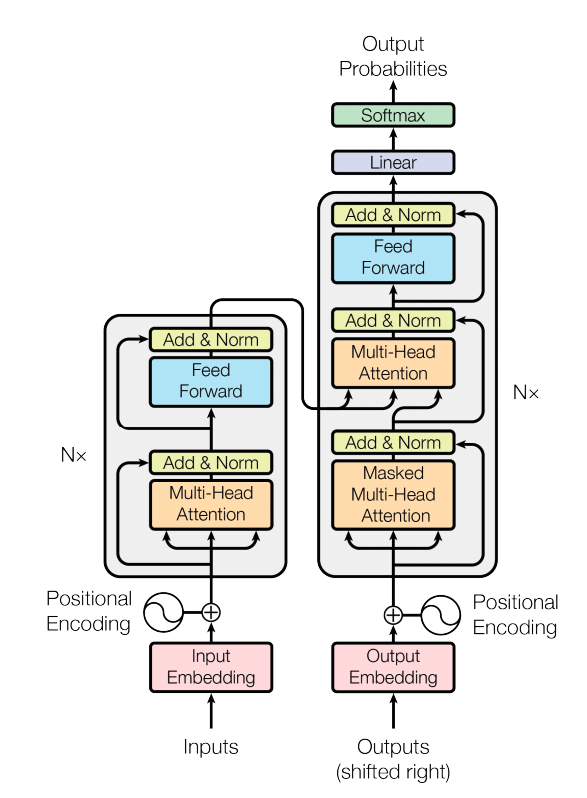
L’attention masquée
- Pendant l’entraînement le modèle à accès aux phrases complètes
- Empêche le modèle de “voir le futur”
- Chaque position ne peut voir que les positions précédentes
- Crucial pour la génération de texte
- C’est une matrice de masquage multipliée avec les scores d’attention
"Le chat dort sur le"
↑ ↑ ↑ ↑ ↑
"canapé"Pour prédire “canapé” :
- Peut voir : “Le chat dort sur le”
- Ne peut pas voir : les mots futurs
L’attention croisée
- Permet au décodeur de “regarder” l’encodeur
- Relie la sortie à l’entrée
- Pas de masquage ici
Positional Encoding
- Ajoute l’information de position
- Utilise des fonctions sinusoïdales
- Permet au modèle de comprendre l’ordre des mots
Visualisation
https://poloclub.github.io/transformer-explainer/
Cette page illustre et explique les différents concepts d’une architecture transformer.
A toi de jouer
Les règles
- Objectif : Construire un LLM permettant de générer un script pour Kaamelott ou Shakespear
- Construire ?! Bon ok, on va plutot finetune GPT-2
Crédits
- Sopra Steria
- Avec l’aide de ChatGPT4
- (Beaucoup d’aide de ChatGPT4)